AvantGraph: the Next-Generation Graph Analytics Engine
AvantGraph: the Next-Generation Graph Analytics Engine
In a webinar for SciLake partners,Nick Yakovets, Assistant Professor at the Department of Mathematics and Computer Science, Information Systems WSK&I at Eindhoven University of Technology (TU/e), introducedAvantGraph, a next-generation knowledge graph analytics engine.Yuanjin Wu andDaan de Graaf, graduate students in Nick's research group, presented a demo of the tool.
Developed by TU/e researchers, AvantGraph aims to provide a unified execution platform for graph queries, supporting everything from simple questions to complex algorithms. In this blog post, we will delve into the philosophy behind AvantGraph, its query processing pipeline, and its impact on graph analytics.
The Philosophy: Questions over Graphs
The fundamental purpose of a database is to answer questions about data. For a graph database like AvantGraph, the focus is on asking questions over graphs. We can categorize these questions based on theirexpressiveness, and the degree to which databases canoptimize their execution. Expressiveness refers to the richness and difficulty of the questions being asked, while optimization refers to how easy or difficult it is for databases to answer these questions. Based on this categorization, the range of questions that can be asked over graphs varies in complexity, as shown in the graphic below, from simple local look-ups to general algorithms that introduce iterations:
- Local look-ups (e.g., the properties of data associated with a full text)
- Neighborhood look-ups
- Subgraph isomorphism (matching specific patterns of the graph)
- Recursive path queries (introducing connectivity)
- General algorithms (introducing iterations, e.g.,PageRank)

Optimization level as a function of questions’ complexity.
AvantGraph aims to cover this full spectrum of questions, allowing users to optimize the execution of their queries and explore the richness of their data. It utilizes cutting-edge technologies to enable efficient processing of very large graphs on personal laptops.
AvantGraph Query Processing Pipeline
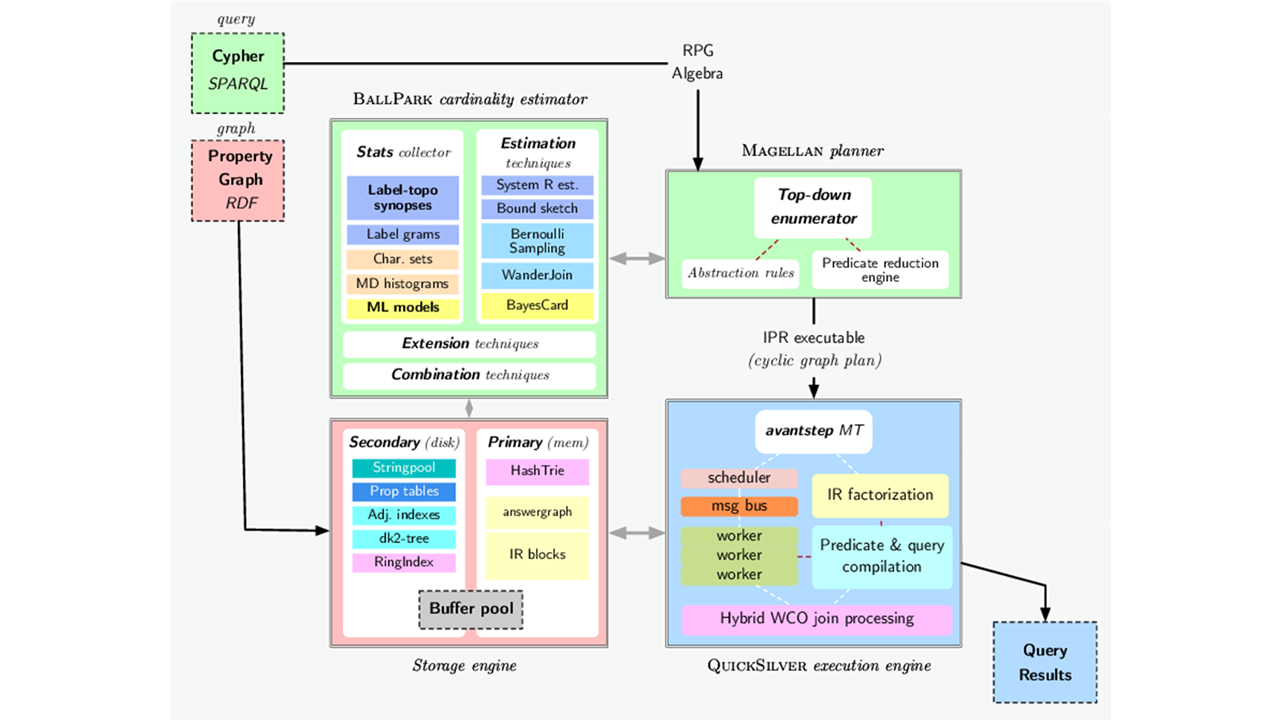
AvantGraph query processing pipeline, adapted fromDOI:10.14778/3554821.3554878
AvantGraph employs a standard database pipeline. It supports query languages likeCypher andSPARQL, and it features three additional main components to enable the execution of complex questions like algorithms:
- theQuickSilver execution engine, a multi-thread execution system allowing for efficient query parallelization and hardware utilization;
- the Magellan Planner, a query optimizer that returns efficient execution plans tailored to each query, taking into account the recursive and iterative nature of graph queries;
- theBallPark cardinality estimator, a cost model that determines the best execution plan for different circumstances, optimizing query performance.
In addition, AvantGraph supports secondary storage, utilizing both memory and disk effectively. This allows it to process very large graphs on laptops without requiring excessive amounts of RAM.
Preparations for SciLake Pilots
As part of the SciLake project, AvantGraph is being extended with powerful data analytics capabilities and novel technologies to support research communities in defining graph algorithms.
Why do we need it?
Graph query languages such as Cypher or SPARQL are specifically designed for "subgraph matching". This makes them highly effective when you need to retrieve information such as "get me the neighbors of a specific node" or "find the shortest path between two nodes in the graph". However, unfortunately, these query languages are too limited for complex graph analytics like e.g., PageRank.
Traditional solutions to this issue involve the database vendor providing a library of built-in algorithms that can be applied to the graph. While this works well if the library includes the algorithm needed to solve the problem, it cannot accommodate simple variations or fully custom algorithms.
What AvantGraph offers
AvantGraph introducesGraphalg, a programming language designed specifically for writing graph algorithms. Graphalg is fully integrated into AvantGraph, meaning, for example, that it can be embedded into Cypher queries.
The language used in Graphalg is based on linear algebra, which makes the syntax and operations easy to learn. The goal for Graphalg is to be a high-level language that is both user-friendly and efficiently executed by a database. This is achieved by transforming queries and Graphalg programs into a unified representation that can be optimized effectively. This enables optimizations that cross the boundary between query and algorithm, that would not otherwise be possible.
AvantGraph supports the client-server model, which is commonly used by most modern database engines, including Postgres, MySQL, Neo4j, Amazon Neptune, Memgraph, and more. This allows AvantGraph databases to be queried through more than just a Command Line Interface.
As of now, AvantGraph databases can be queried from most major programming languages, including Python API, and will be expanded in the future with more algorithms and functionalities.
Conclusion
AvantGraph represents a significant advancement in knowledge graph analytics. By addressing the limitations of traditional graph query languages and introducing Graphalg, AvantGraph empowers users to perform complex graph analytics with ease. Its unified execution of simple questions to general algorithms, coupled with its efficient query processing pipeline, makes it a valuable tool for researchers and data scientists. As AvantGraph continues to evolve and gain traction within the research community, we can expect to see exciting advancements in graph analytics and a deeper understanding of complex data relationships.
Learn more
AvantGraph is presented in:
Leeuwen, W.V., Mulder, T., Wall, B.V., Fletcher, G., & Yakovets, N. (2022). AvantGraph Query Processing Engine.Proc. VLDB Endow., 15, 3698-3701.
For more information about AvantGraph and its publications, visit https://avantgraph.io/.
AvantGraph will be released under an open license soon. To test its functionalities and perform graph queries, check out the docker container available on GitHub at https://github.com/avantlab/avantgraph/.